
Patient Data Security and Cybersecurity in AI Triage
The integration of Artificial Intelligence (AI) into patient triage workflows is rapidly becoming an operational necessity for optimizing resource allocation in high-pressure environments, such as Emergency Departments (EDs).


The integration of Artificial Intelligence (AI) into patient triage workflows is rapidly becoming an operational necessity for optimizing resource allocation in high-pressure environments, such as Emergency Departments (EDs). Evidence confirms that AI triage systems offer quantifiable clinical advantages, including enhanced accuracy, reducing mis-triage rates to 0.9% compared to 1.2% for traditional methods, and demonstrating superior capability in predicting critical care needs. However, this clinical benefit is achieved at the cost of significantly expanding the cyber attack surface and introducing novel, high-risk security vectors that fundamentally challenge traditional healthcare compliance models, such such as those established under HIPAA and the General Data Protection Regulation (GDPR).
The central strategic risk stems from the inherent conflict between the regulatory demands for mandatory human intervention and detailed transparency (specifically under GDPR Article 22) and the operational requirement for rapid, automated triage efficiency. Successfully navigating this dichotomy requires immediate architectural shifts. Enterprise security posture must move beyond simple perimeter defense to mandate privacy-enhancing technologies (PETs) like Federated Learning (FL) for collaborative training and advanced encryption protocols to guarantee model integrity and ensure data utility without sacrificing confidentiality.
The AI Triage Ecosystem and Sensitive Data Flow
Defining AI-Driven Clinical Triage: Functionality and Operational Benefits
AI triage systems are sophisticated clinical decision support tools designed to process vast amounts of patient data rapidly to determine the potential severity of a condition and suggest appropriate urgency levels. Unlike traditional triage systems that rely solely on human assessment by a receptionist or nurse, AI models can rapidly process detailed symptom information, often supplied by the patient in their own words, against comprehensive medical knowledge bases.
The clinical value derived from this efficiency is substantial. AI-powered machine learning models consistently outperform conventional tools, such as the Emergency Severity Index, in forecasting critical care needs and hospitalization outcomes. This capacity translates directly into improved patient safety by reducing under-triage rates—showing heightened sensitivity in identifying critically ill patients—while simultaneously addressing issues of over-triage. Furthermore, integrating technologies like Voice-AI into documentation processes has demonstrated operational efficiency gains, achieving 19% faster documentation compared to manual methods, freeing up clinical resources. Despite these compelling benefits, the deployment of AI triage remains subject to practical limitations, including variable accuracy across different implementations, residual risks of undertriage, and pervasive challenges related to effective workflow integration within existing clinical environments.
Data Input, Processing, and Output Requirements
The functioning of any AI triage system necessitates the handling of highly sensitive patient information across its lifecycle: training, inference, and output. To ensure equitable treatment recommendations, AI models must be trained on diverse data that accurately represents the full spectrum of patient populations. Inputs during the operational (inference) phase include detailed, real-time clinical data such as patient-reported symptoms , key biomarkers, and comprehensive data needed for prediction precision.
The data outputs generated by these systems are profoundly consequential, directly determining the subsequent clinical pathway and resource allocation for the patient. Outputs include suggested urgency levels (e.g., Red, Yellow, Green categories) , real-time predictions of disease severity and progression, estimations of hospitalization length, and the calculated likelihood of a patient requiring admission to an Intensive Care Unit (ICU).
The context of patient data security is fundamentally altered by the nature of these outputs. Health information (PHI) is already a primary target for cyber attackers. When AI triage operates, it not only processes existing PHI but actively generates new, highly sensitive PHI in the form of prognostic data. For example, a prediction of a high likelihood of ICU admission or an estimated length of stay is generated insight that is often more valuable and damaging if leaked than the raw input data alone. This generated data represents both a critical clinical assessment and proprietary intellectual property (IP) belonging to the system and the healthcare institution. Therefore, a breach involving AI outputs carries significant liability, as it exposes the patient's future clinical trajectory and reveals the proprietary model logic underpinning the prediction. Consequently, security architecture must treat AI outputs (inference data) with an equal or greater degree of protection—demanding stringent encryption, access control, and mandatory output validation—than that applied to the original source data.
Navigating the Global Regulatory Mandate for AI in Healthcare
Foundational Pillars: Global Compliance Frameworks
The deployment of AI in healthcare operates under stringent international privacy and security regulations.
The European Union’s GDPR establishes foundational requirements for data handling, mandating explicit and granular consent for the collection of sensitive health data. Crucially, it defines the patient's right to transparency, requiring organizations to inform individuals precisely how AI systems process their data. Following Brexit, the GDPR was enacted into UK law as the Data Protection Act 2018 (DPA). UK law works in conjunction with the NHS Data Security and Protection Toolkit (DSPT) and the established requirements for Caldicott Guardians, emphasizing the essential nature of robust personal data protection practices as AI developments increase data collection. The UK’s Information Commissioner’s Office (ICO) provides specific guidance on AI and Data Protection, underscoring the necessity of fairness, transparency, and explainability in the use of AI systems, particularly those dealing with special category data.
The global context introduces significant complications. Cross-border use of AI data—for training or deployment across multinational systems—is complicated by varying international regulations, such as the strict standards of GDPR differing from those of HIPAA in the United States. Healthcare organizations must maintain a robust strategy of regular audits and continuous updates to their security protocols to maintain compliance in this highly dynamic and complex regulatory environment.
Deep Dive into GDPR Article 22: Restrictions on Solely Automated Decision-Making
GDPR Article 22 (1) and (3) establish a critical safeguard: the data subject (the patient) has the fundamental right not to be subject to a decision based solely on automated processing, including profiling, if that decision produces legal effects concerning them or similarly significantly affects them.
Automated decision-making based on health data is permissible only under tightly controlled legal exceptions. These conditions stipulate that the processing must be strictly necessary for contractual purposes, explicitly authorized by EU or Member State law, or based on the data subject's explicit consent. Furthermore, transparency is a non-negotiable requirement. Data controllers must provide the patient with "meaningful information about the logic involved, as well as the significance and the envisaged consequences" of the automated processing.
This mandate creates a critical conflict with the speed-driven nature of AI triage. The foundational efficiency benefit of using AI in triage is rooted in rapid assessment and automation. However, the AI’s suggested urgency level directly and significantly affects the patient’s treatment priority and wait time, qualifying it as a decision that "significantly affects" the patient under Article 22. To achieve GDPR compliance, the triage process must ensure a human clinician validates, reviews, or explicitly overrides the AI's recommendation, preventing the decision from being deemed solely automated. In high-volume, time-critical ED settings, the regulatory demand for providing detailed transparency and explainability in real-time fundamentally clashes with the necessary speed of emergency triage. Consequently, healthcare organizations must strategically define the AI’s function strictly as decision support, rather than an automated decision-maker, and must formalize mandatory clinical acceptance and override procedures to ensure compliance while retaining the speed benefits of the recommendation.
The EU AI Act and High-Risk Classification
The emerging regulatory landscape, particularly the European Union’s AI Act, directly impacts AI triage systems. Systems that significantly impact health and safety, such as those performing patient prioritization, are classified as "high-risk" under the Act. This classification imposes a significant compliance burden on system manufacturers, who must adhere to stringent requirements concerning data governance and comprehensive risk management throughout the entire product lifecycle. This emphasis on lifecycle management aligns with international trends; for instance, guidelines published by the Centre for Medical Device Evaluation under the NMPA in China also standardize the regulation of AI medical devices (AI-MDs), focusing on risk factors and Total Product Lifecycle (TPLC) management.
Cybersecurity Threat Modeling for AI Triage Systems
AI triage systems introduce unique vulnerabilities that necessitate a comprehensive re-evaluation of cybersecurity strategies, extending beyond traditional network defense to encompass threats targeting the integrity of the machine learning models themselves.
Traditional Threat Surface Expansion: API Security
AI systems fundamentally rely on Application Programming Interfaces (APIs) for interoperability, allowing for seamless data exchange with Electronic Health Records (EHRs) and other clinical platforms. This essential reliance, however, significantly expands the attack surface. As APIs proliferate across applications, cloud environments, and AI models, the operational risk dramatically increases.
AI triage systems are vulnerable to a range of common API risks, including Injection attacks, where malicious code or data is fed into an API request; Broken authentication and session management, allowing attackers unauthorized access; and Insecure communication, where data is transmitted over unencrypted connections. A critical concern is the lack of proper validation of forward input, which can allow malicious data to be inserted into requests. Organizations frequently operate without a comprehensive inventory of their active APIs, making it easier for misconfigured or poorly protected endpoints to be exploited for data theft or disruption of operations. Successful API attacks can expose not only personal medical records and health histories but also proprietary business information, including the AI model’s intellectual property.
AI-Native Threats: Manipulation of Model Integrity
The unique vulnerabilities of Machine Learning (ML) models introduce sophisticated threats that can directly compromise patient safety and decision integrity.
Adversarial Attacks are malicious techniques engineered to manipulate ML models by feeding them deceptive data inputs, causing incorrect or unintended behavior. These attacks exploit subtle, often imperceptible changes to the input data to bypass detection mechanisms. In clinical practice, this has been demonstrated through research showing how minute noises added to medical images can misclassify a benign mole as malignant with high confidence. Applied to triage, an attacker could subtly alter symptom details, either directly or via a compromised API, to force a critically unstable patient into a low-priority "Green" triage category, leading directly to patient harm. Furthermore, if the training data pipeline is compromised, the threat of Model Poisoning exists, where data integrity is intentionally corrupted to bias the model or degrade its accuracy, creating systemic flaws after deployment.
Data Leakage Vectors: Training Data Memorization and Inferring PHI
AI models trained extensively on patient records face the risk of Data Memorization, where fragments of sensitive personal health information (PHI) are inadvertently stored within the model’s parameters. Although the training data may appear sanitized, malicious actors can craft specific inputs or "prompts" designed to extract these memorized sensitive details, such as patient names, diagnoses, or specific treatment plans.
A related vector is the misuse of general-purpose Large Language Models (LLMs) in clinical settings. Employees or executives may inadvertently paste confidential documents or sensitive patient queries into open LLMs (like consumer-grade chatbots), placing PHI into the public domain and forfeiting control over the sensitive data. Case studies, such as the DeepSeek data exposure in 2024, underscore the devastating consequences of unsecured configurations, which exposed over one million records including user prompts and system logs. If a healthcare AI system were to suffer a similar exposure, attackers could extract specific patient queries or AI-assisted diagnostic results, resulting in severe privacy violations.
The escalation of cyber threats, driven by cybercriminals increasingly leveraging generative AI to automate attacks, craft sophisticated malware, and create highly convincing deepfakes, fundamentally raises the security bar for healthcare organizations. This offensive capability, which lowers the skill threshold for developing advanced threats, means that traditional perimeter defenses are insufficient. Consequently, the defense strategy must embrace defensive AI. AI-enabled incident triage systems are now essential tools within the Security Operations Center (SOC) to automatically score and prioritize alerts, accelerate investigation by 55%, and trigger automated containment responses like isolating infected endpoints. The security of the AI triage system used clinically thus becomes inextricably linked to the efficacy of the SOC’s defensive AI systems. If the defensive infrastructure fails to accurately and rapidly triage a sophisticated attack—such as an adversarial input attack—the clinical AI model remains exposed and patient safety is jeopardized. This tight coupling necessitates a unified, layered security architecture.
Implementing Secure AI Architecture and Cryptographic Controls
Secure-by-Design Principles for Clinical AI Systems
The security of clinical AI must be structurally embedded from the inception of the project. Before any AI system achieves live status, it must be grounded in a robust security framework that explicitly defines roles, safeguards, and risk profiles. Every architectural layer, encompassing data storage, processing pipelines, and traffic routing, must align rigorously with confidentiality and integrity requirements.
Data Protection Framework
Core encryption protocols are non-negotiable standards for handling sensitive health data. Implementation must mandate AES-256 for data at rest and TLS 1.3 for data in transit, with all legacy and older TLS versions being immediately retired from configuration. Encryption keys must be managed through dedicated key management services. Furthermore, robust Identity and Access Management (IAM) platforms must automate the enforcement of access control matrices, which are necessary for defining granular user roles and corresponding resource permissions. All changes to access control must be logged and reviewed systematically.
Training Data Protection and Inference Protection
Training data requires mandatory anonymization, utilizing advanced techniques such as structured redaction or differential privacy, before the data enters the training pipelines. For securing processed data and raw inputs, secure storage protocols mandate encryption at rest. Going further, the deployment of confidential computing environments is highly recommended, ensuring that data remains encrypted even while being actively processed, significantly mitigating the risk of data memorization leakage.
For inference protection, model encryption is essential to protect the model’s intellectual property (IP) and restrict unauthorized use. Models must be encrypted both at rest and in transit, with decryption permitted only inside approved, tightly controlled environments. Critically, output validation must be implemented as a mandatory control to prevent harmful or malformed AI responses from reaching clinical users or downstream systems. All AI outputs should be filtered against allowed values and business logic to maintain clinical safety.
Privacy-Preserving Techniques (PETs) in Data Pipelines
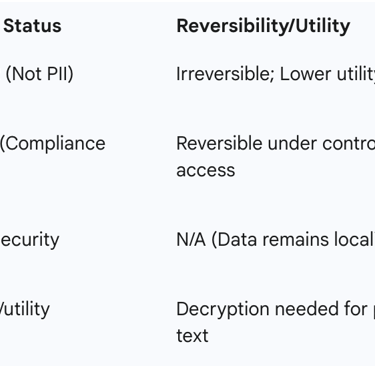
Organizations must make a critical strategic determination between anonymization and pseudonymization based on regulatory exposure and the required data utility.
Anonymization is an irreversible process that completely removes all identifying information, making it impossible to trace the data subject. Once anonymized, data is no longer classified as PII and is exempt from GDPR regulations, making it suitable primarily for external dataset sharing or public research where reversibility is not required.
Pseudonymization, conversely, is a recognized technique under GDPR for reducing compliance burden, but the resulting data remains classified as PII because it is reversible under controlled conditions. Pseudonymization replaces sensitive identifiers with tokens that can be mapped back to the original data using strict access controls, making it ideal for internal development, testing, and continuous monitoring where re-identification might be necessary for debugging or insider risk management.
Tokenization is a valuable technique employed in both processes, replacing sensitive data with randomly generated tokens not derived from the original information but linked securely to it.
The strategic selection of the appropriate technique depends on the specific use case within the AI lifecycle:
Table: Strategic Use Cases for Privacy-Enhancing Technologies (PETs)

Decentralized Training: The Strategic Advantage of Federated Learning (FL)
Federated Learning (FL) offers a powerful solution to the dual challenges of data privacy and the need for diverse training data. FL is a decentralized machine learning approach that allows multiple organizations or devices (such as servers at different hospital sites) to train an AI model collaboratively without the underlying private data ever being shared directly between them. Only the model updates or parameters are exchanged and aggregated centrally.
This approach significantly alleviates privacy and security concerns associated with handling sensitive medical data. By leveraging data from multiple settings, FL improves reproducibility and ensures the models are generalizable across diverse patient populations, a critical factor for ensuring AI triage is equitable and effective in real-world environments.
The Future of Processing: Fully Homomorphic Encryption (FHE)
The most advanced cryptographic solution for data utility is Fully Homomorphic Encryption (FHE). FHE is the most robust form of homomorphic encryption, capable of supporting an infinite number of analytical operations for an infinite duration. This capability allows analytical functions to run directly on encrypted data, yielding an encrypted result identical to what would be achieved if the functions were run on plaintext.
FHE holds transformative promise for healthcare, enabling organizations to leverage data from multiple institutions to fuel AI tools, bypassing stringent data privacy regulations that typically restrict data sharing. While currently resource-intensive, research is actively investigating the feasibility and performance of deploying FHE in neural network algorithms for healthcare diagnostics. FHE represents the strategic objective for achieving maximal data utility while maintaining absolute security, potentially eliminating the need to expose PHI during computation entirely.
Governance, Accountability, and Operational Risk Management
5.1 Establishing Multidisciplinary AI Governance Structures
Effective governance is fundamental for the safe, trustworthy, and impactful adoption of AI in clinical settings. The governance structure must be integrated seamlessly into the health system’s existing ecosystem, rather than functioning as an isolated or ad hoc effort. It requires a multidisciplinary composition, bringing together critical stakeholders including clinical leadership, medical informatics, legal counsel, compliance experts, data scientists, bioethics specialists, and patient advocates.
Models such as the Governance Model for AI in Healthcare (GMAIH) emphasize four core components: fairness, transparency, trustworthiness, and accountability. Governance must be structured to prioritize patient outcomes over isolated, technical model performance metrics. This involves rigorous pre-implementation validation, establishing explicit go/no-go thresholds, and continuous monitoring post-deployment to assess the actual impact on the patient population. A key function of governance is the clarification of accountability: who is responsible for control, how harm is reported, and the formal process for escalation when AI performance issues arise. The process of accountability and reporting should mirror established clinical governance strategies, including the incorporation of patient views and robust education and training for clinicians.
5.2 Integrating AI Risk Management Frameworks (NIST AI RMF)
To manage the novel and multifaceted risks introduced by AI, organizations must adopt structured frameworks like the NIST AI Risk Management Framework (RMF). The RMF provides guidelines for purposefully allocating resources and systematically assessing the trustworthiness of every deployed AI system. Key measures within the framework demand the rigorous evaluation and documentation of AI system security and resilience (Measure 2.7), and a thorough examination and documentation of risks associated with transparency and accountability (Measure 2.8). A culture of risk management recognizes that not all AI risks are equivalent, allowing resources to be allocated based on the assessed risk level and potential clinical impact.
Roles and Responsibilities in the AI Lifecycle
The integration of AI introduces complex questions regarding liability, particularly when an AI misclassification leads to patient harm, a situation complicated by the fact that frameworks addressing liability for AI use (like the EU liability directive) are still under development. The convergence of the AI developer (responsible for model integrity) and the hospital’s IT/Clinical staff (responsible for operational environment and final clinical judgment) necessitates a precise, contractual, and procedural separation of duties.
If an adversarial attack causes a technical failure that leads to clinical harm, ambiguity surrounding accountability poses a significant legal and patient safety risk. Therefore, contracts with AI vendors must explicitly delineate security responsibilities—specifying who is responsible for patching the model versus hardening the API gateway—and clearly establish formal escalation paths for performance degradation.
The table below outlines the necessary delineation of security responsibilities across key organizational stakeholders:
Table: Stakeholder Accountability Matrix for AI Triage Systems


Continuous Auditing and Monitoring for Clinical AI
Continuous monitoring is essential to ensure both sustained security and consistent clinical performance. AI systems must be designed to create comprehensive audit trails, meticulously documenting all activities related to patient data access and AI-driven decisions. These trails are critical for compliance reporting (e.g., HIPAA) and forensic investigation following an incident.
Furthermore, organizations should leverage AI-enabled risk-based auditing to enhance their compliance posture. Machine learning models can analyze vast amounts of data to predict compliance risks and automatically flag anomalies in access patterns. This includes crucial access pattern monitoring that protects patient data by identifying unusual activity, such as an employee accessing an uncommonly high number of records or viewing patient files outside their domain of care, thereby mitigating insider risk. Post-deployment monitoring must track the AI model's performance metrics over time, providing clear signals when the model begins to underperform or exhibit emergent algorithmic bias.
Strategic Recommendations and Future Outlook
6.1 Immediate Action Plan for Triage AI Deployment
Compliance Formalization: Organizations must immediately formalize internal policies defining the precise mechanism of "human intervention" required to validate the AI triage recommendation. This ensures the system functions strictly as high-speed decision support, maintaining compliance with GDPR Article 22 by preventing the decision from being based solely on automated processing.
API Inventory and Hardening: Given the expansive threat surface posed by APIs, security teams must deploy comprehensive API security solutions to generate a full inventory of all active APIs, analyze the sensitive data flows traversing them, and immediately mitigate against critical flaws such as injection vulnerabilities and broken authentication mechanisms.
Adversarial Defense Implementation: To safeguard against deliberate manipulation, security architects must implement mandatory input validation and specialized anomaly detection controls designed to identify and filter adversarial inputs before they reach the clinical AI model, thereby protecting the triage system from forced misclassification.
Investment Priorities in Privacy-Enhancing Technologies (PETs)
The strategic shift requires significant investment in advanced PETs to balance data utility with privacy:
Prioritize Federated Learning (FL): Immediate investment in FL infrastructure is necessary to enable multi-center collaboration. This allows the organization to train and validate models on diverse, distributed datasets, improving the model's generalizability and accuracy while ensuring localized data privacy is maintained.
Adopt Confidential Computing: Deployment of confidential computing environments is critical to mitigate key risks such as training data memorization, guaranteeing that sensitive patient data and model parameters remain protected through encryption even during active processing.
Establish FHE Roadmap: Dedicated Research and Development (R&D) resources should be allocated to tracking and piloting the viability of Fully Homomorphic Encryption (FHE). Positioning the organization to adopt FHE ensures readiness to leverage maximum data utility for high-value analytical tasks as cryptographic performance overhead decreases.
Recommendations for Policy Advocacy and Regulatory Alignment
Proactive Risk Governance: Utilization of the NIST AI Risk Management Framework (RMF) should be mandated across the organization to systematically structure and prioritize risk management efforts. This ensures that transparency and accountability standards are evaluated and documented alongside technical security and resilience.
Multidisciplinary Education: Mandatory, targeted training must be implemented across all teams—clinical, IT, legal, and administrative—to educate staff on the unique risks posed by AI, including the mechanics of adversarial attacks and data memorization. This strategy is essential for fostering a comprehensive, risk-aware organizational culture.
Continuous Equity and Bias Monitoring: The governance framework must include ongoing bias monitoring, extending beyond initial validation, to continuously ensure the AI system, trained on diverse populations, maintains equitable performance and outcomes for all patient demographics post-deployment.